
Introduction
Security Operations Centers (SOCs) are designed to identify, investigate, and respond to security threats before they impact business operations. However, as organizations continue to expand their digital infrastructure, SOC teams face a growing challenge: alert fatigue.
Modern security environments generate thousands of alerts daily from endpoint detection platforms, SIEM solutions, cloud security tools, vulnerability scanners, identity providers, and network monitoring systems. A significant percentage of these alerts are false positives, redundant notifications, or low-priority events that require no immediate action. The result is an overwhelming volume of noise that consumes analyst resources, delays incident response, and increases the risk of missing genuine threats.
[Raw Linux Telemetry (Syscalls, Logs)]
│
▼
[Generic Atomic Detection Rules] ──► Massive False Positive Noise (Alert Fatigue)
│
▼
[Zero-Noise: Context + Lineage + eBPF] ──► High-Fidelity, Actionable Incidents
According to multiple industry studies, SOC analysts spend a substantial portion of their time triaging alerts that ultimately prove benign. This operational inefficiency contributes to analyst burnout, reduced detection effectiveness, and longer mean time to detect (MTTD) and mean time to respond (MTTR).
In this blog, we will explore the causes of SOC alert fatigue, examine how Linux-centric environments contribute to alert volume, and discuss practical strategies for implementing Zero-Noise Operations. We will also cover automation, detection engineering, Linux telemetry optimization, and operational best practices that enable security teams to focus exclusively on high-confidence threats.
Understanding SOC Alert Fatigue
SOC alert fatigue occurs when analysts are exposed to excessive volumes of security notifications, many of which provide little investigative value. Over time, continuous exposure to non-actionable alerts reduces analyst efficiency and increases the likelihood that critical incidents will be overlooked.
Common indicators of alert fatigue include:
- Large alert queues with significant backlogs
- Excessive false-positive rates
- Increased investigation times
- Repeated manual triage activities
- Analyst burnout and turnover
- Missed or delayed detection of genuine threats
The challenge is not simply the number of alerts generated but the signal-to-noise ratio within the security monitoring ecosystem.
A SOC receiving 20,000 alerts per day may only encounter a handful of events requiring immediate investigation. Without effective filtering and prioritization mechanisms, analysts are forced to spend valuable time distinguishing meaningful signals from operational noise.
Why Linux Environments Generate Significant Security Noise
Linux systems form the foundation of modern enterprise infrastructure. They power:
- Cloud workloads
- Kubernetes clusters
- Web servers
- Database platforms
- Containerized applications
- High-performance computing environments
- Security appliances
The operational complexity of these environments often results in large volumes of telemetry.
1. High Process Activity
Linux systems continuously generate process creation events, service executions, scheduled jobs, and daemon activities.
Examples include:
- systemd service startups
- Cron job execution
- Package manager operations
- Container lifecycle events
- Automated maintenance tasks
Without proper tuning, these legitimate activities frequently trigger endpoint detection rules.
2. Dynamic Cloud Workloads
Cloud-native Linux workloads are highly ephemeral.
Containers may:
- Start and stop within seconds
- Receive dynamic IP addresses
- Generate temporary filesystems
- Spawn short-lived processes
Security tools often interpret these normal behaviors as suspicious due to their transient nature.
3. Administrative Automation
Organizations rely heavily on automation tools such as:
- Ansible
- Puppet
- Chef
- Terraform
- Kubernetes Operators
These platforms routinely execute privileged commands across thousands of systems. Detection rules that lack environmental awareness often generate unnecessary alerts from approved administrative actions.
4. Open-Source Tooling
Linux administrators frequently use open-source utilities that may resemble attacker tradecraft.
Examples include:
- Netcat
- Curl
- Wget
- SSH tunneling
- Tcpdump
- Socat
While legitimate in administrative workflows, these tools are also commonly leveraged during attacks, making contextual analysis essential.
The Strategic Core of Zero-Noise Operations
Zero-Noise Operations does not mean suppressing security visibility or blinding your logging pipeline. Instead, it is an engineering discipline focused on shifting your pipeline from volume-driven logging to precision-focused detection.
| Telemetry Layer | Performance Overhead | Contextual Visibility | Primary Use Case |
| Auditd (Linux Audit) | High (under heavy I/O) | High (System Calls) | Traditional compliance, user command auditing |
| Sysmon for Linux | Moderate | Very High (Structured JSON) | Host-level process creation and network correlation |
| eBPF (e.g., Tetragon / Falco) | Extremely Low | Elite (Kernel space + K8s context) | Real-time cloud-native runtime protection |
The Cost of Excessive Alert Noise
Alert fatigue creates measurable business and security risks.
Delayed Incident Response
When analysts spend excessive time investigating low-value alerts, genuine incidents remain undetected for longer periods.
Attackers benefit directly from increased dwell time.
Reduced Detection Effectiveness
Security teams may begin ignoring alerts that historically prove benign.
This behavior increases the probability of overlooking malicious activity hidden within similar events.
Analyst Burnout
Repeated manual triage of false positives creates operational fatigue.
SOC personnel often experience:
- Reduced productivity
- Lower morale
- Higher turnover rates
- Increased training costs
Increased Operational Expenses
Organizations frequently respond to alert overload by hiring additional analysts rather than addressing underlying detection quality issues.
This approach increases operational costs without improving security outcomes.
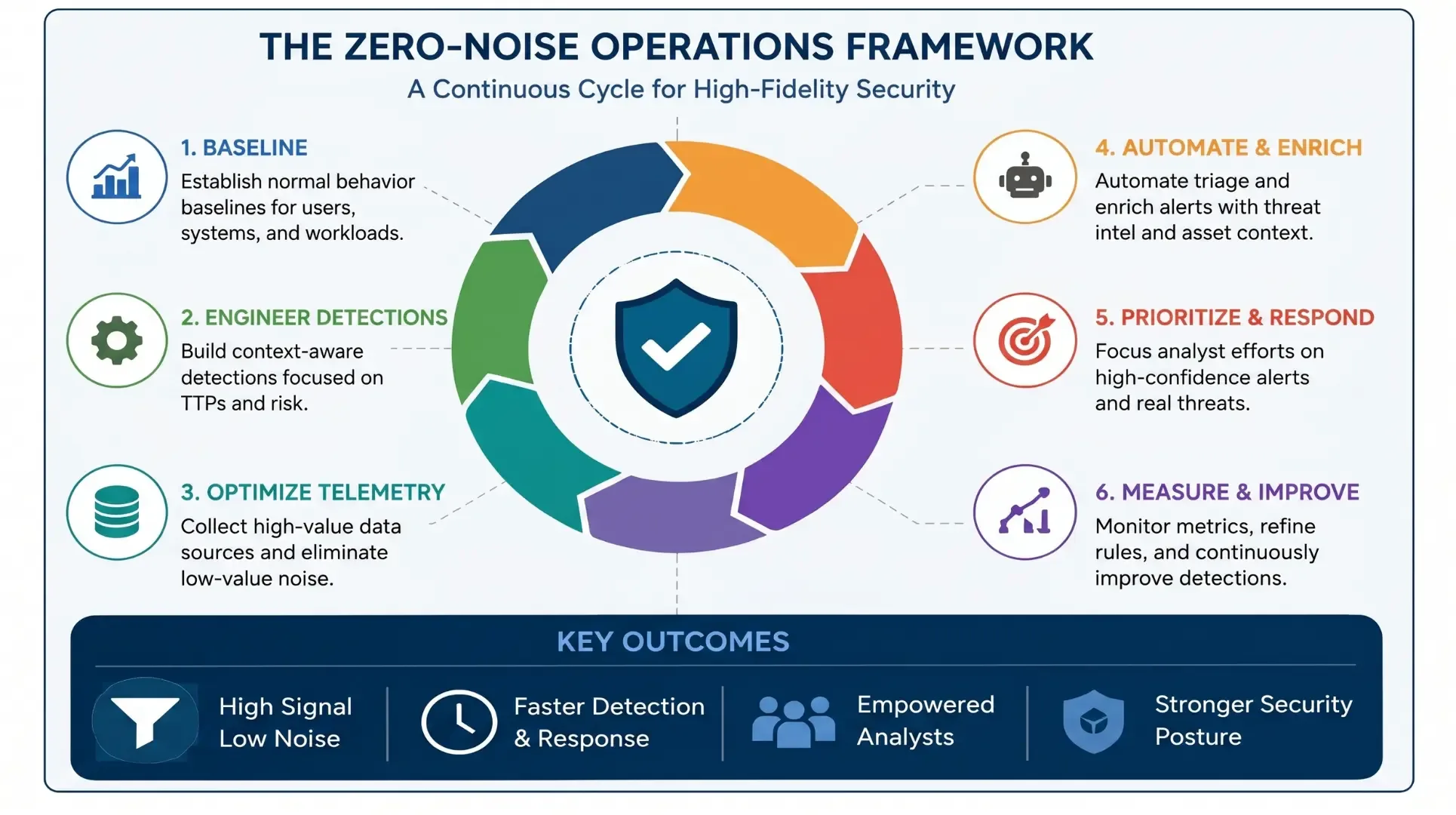
What Is Zero-Noise Operations?
Zero-Noise Operations is a security strategy focused on eliminating non-actionable alerts and maximizing analyst attention toward verified security threats.
The objective is not to suppress security visibility.
Instead, the goal is to ensure that every alert entering the SOC has a meaningful probability of representing malicious activity.
Zero-Noise Operations relies on:
- Detection engineering
- Telemetry optimization
- Behavioral baselining
- Context enrichment
- Automated triage
- Threat-informed monitoring
The end result is a security operation where analysts investigate fewer alerts but achieve significantly higher detection accuracy.
Building a Linux-Focused Zero-Noise SOC
1. Establish Accurate Behavioral Baselines
Effective detection begins with understanding normal system behavior.
Linux environments should be baselined for:
- Process execution patterns
- User activity
- Network connections
- Service startups
- Scheduled tasks
- Container behavior
By identifying normal operational patterns, security teams can significantly reduce false-positive rates.
For example:
A Kubernetes node routinely launching hundreds of containers daily should not generate alerts solely due to process creation volume.
Instead, detections should focus on anomalous deviations from established baselines.
2. Improve Detection Engineering
Poorly designed detection rules are a primary source of SOC noise.
Traditional rules often trigger based on:
- Single command executions
- Individual process launches
- Isolated network connections
Modern detection engineering should incorporate context.
Rather than alerting on every execution of curl, a detection might require:
- Curl downloading an executable
- Subsequent permission modification
- Immediate execution of the downloaded file
This behavioral correlation significantly increases alert fidelity.
Linux detection content should emphasize:
- Privilege escalation attempts
- Unauthorized persistence mechanisms
- Suspicious container activity
- Credential access techniques
- Defense evasion behaviors
- Lateral movement indicators
3. Implement Telemetry Reduction Strategies
Collecting excessive data does not automatically improve security visibility.
Organizations should focus on high-value telemetry sources such as:
Linux Audit Framework (auditd)
Monitor:
- Privileged command execution
- Sensitive file access
- Authentication activity
- Configuration changes
eBPF-Based Monitoring
Extended Berkeley Packet Filter (eBPF) technology enables low-overhead visibility into:
- Process execution
- File access
- Network activity
- Kernel interactions
Modern platforms increasingly leverage eBPF to provide richer context while reducing performance overhead.
Sysmon for Linux
Sysmon for Linux provides detailed event collection capabilities similar to its Windows counterpart.
When properly configured, it enables highly targeted monitoring without generating excessive noise.
4. Enrich Alerts with Context
Analysts should never investigate alerts in isolation.
Every alert should include contextual information such as:
- Asset criticality
- User identity
- Container metadata
- Cloud workload ownership
- Threat intelligence matches
- Historical activity
For example, a root-level shell execution on a production payment server carries significantly different risk than the same activity on a development environment.
Context-driven prioritization dramatically improves analyst efficiency.
5. Automate Repetitive Investigations
Security Orchestration, Automation, and Response (SOAR) platforms play a critical role in reducing alert fatigue.
Common automated workflows include:
- Threat intelligence lookups
- Hash reputation checks
- Domain analysis
- User verification
- Process validation
- Asset inventory enrichment
Low-risk alerts can often be automatically closed after predefined validation steps.
This approach allows analysts to focus on complex investigations requiring human judgment.
Leveraging eBPF for High-Fidelity Linux Detection
One of the most effective strategies for reducing Linux security noise is adopting eBPF-based observability.
eBPF provides deep visibility into kernel and user-space activities without requiring intrusive instrumentation.
Benefits include:
- Real-time monitoring
- Reduced overhead
- Fine-grained telemetry
- Improved process correlation
- Enhanced container visibility
Security platforms utilizing eBPF can observe:
- Process lineage
- Network flows
- File modifications
- Privilege transitions
- System call activity
This additional context enables highly precise detections and significantly lowers false-positive rates.
Kubernetes and Container Security Noise Reduction
Containerized environments often amplify alert volume due to their dynamic nature.
Effective monitoring strategies include:
Namespace-Aware Detection
Different namespaces frequently have different security expectations.
Detection rules should account for:
- Production workloads
- Development environments
- System namespaces
Container Behavioral Profiling
Security teams should establish expected behavior profiles for containerized applications.
Alerts should focus on deviations such as:
- Unexpected shell access
- Outbound network connections
- Privilege escalation attempts
- Unauthorized package installation
Runtime Security Controls
Runtime security solutions can enforce policies that prevent suspicious activity before alerts are generated.
This proactive approach reduces both incident volume and analyst workload.
Metrics for Measuring Zero-Noise Success
Organizations should continuously track operational effectiveness.
Key metrics include:
False Positive Rate
Measures the percentage of alerts determined to be benign.
Mean Time to Detect (MTTD)
Evaluates how quickly threats are identified.
Mean Time to Respond (MTTR)
Measures investigation and remediation speed.
Alert-to-Incident Ratio
Tracks how many alerts ultimately become confirmed incidents.
Analyst Workload
Measures alerts investigated per analyst per day.
Successful Zero-Noise initiatives typically demonstrate:
- Lower false-positive rates
- Faster response times
- Improved analyst productivity
- Higher detection confidence
Best Practices for Sustainable Zero-Noise Operations
Organizations pursuing Zero-Noise Operations should adopt the following practices:
- Continuously tune detection rules.
- Remove obsolete monitoring content.
- Establish Linux-specific behavioral baselines.
- Prioritize high-confidence detections.
- Automate repetitive triage workflows.
- Integrate contextual enrichment into all alerts.
- Leverage eBPF for advanced telemetry collection.
- Conduct regular detection validation exercises.
- Measure detection effectiveness using operational metrics.
- Align monitoring strategies with real-world threat intelligence.
Conclusion
SOC alert fatigue remains one of the most significant operational challenges facing modern security teams. As Linux infrastructure, cloud-native architectures, and containerized workloads continue to expand, the volume of generated security telemetry will only increase.
The solution is not to collect more alerts but to generate better alerts.
Zero-Noise Operations represents a shift from volume-driven monitoring to precision-focused detection engineering. By combining behavioral baselining, contextual enrichment, eBPF-powered visibility, intelligent automation, and continuous detection optimization, organizations can dramatically reduce false positives while improving threat detection accuracy.
For Linux-focused environments, achieving Zero-Noise Operations is particularly impactful. High-fidelity telemetry, container-aware monitoring, and threat-informed detections enable SOC analysts to spend less time filtering noise and more time responding to genuine security incidents.
The most effective SOCs are not those processing the highest number of alerts. They are the ones delivering the highest quality security outcomes from the smallest number of actionable events.